|
Архитектура распределенныхсистем управления
Настоящая статья призвана ознакомить читателей с современными распределенными системами управления и проблемами их развития. В статье рассматривается обобщенная структура распреде-ленных систем управления, ее проблемные фрагменты и пути их реализации.
Современные распределенные системы управления находят широкое применение в различных технологических системах, системах автоматизации научных исследований, сложном измерительном оборудовании, в системах малой автоматизации, различных охранных системах и т.д.
Настоящий этап в развитии систем обработки информации характеризуется значительным снижением цен на персональные компьютеры (PC), развитием архитектуры и основных параметров микропроцессорной техники, созданием эффективных высоко интегрированных подсистем первичной обработки аналоговой информации (аналого-цифровых и цифро-аналоговых преобразователей, коммутаторов, генераторов и т.д.), тенденцией к существенному снижению стоимости создаваемых систем [1]. Перечисленные факторы привели к развитию специализированных распределенных систем обработки данных и управления, работающих в реальном масштабе времени (SMMS).
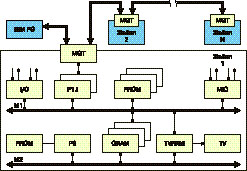
Рис.1. Обобщенная структура современных SMMS
В специальной литературе присутствует достаточно большое число публикаций, анализ которых позволяет сформулировать особенности современных SMMS:
- Обычно такие системы представляют собой специализированные локальные сети (LAN).
- Специализированные LAN, как правило, имеют магистральную (шинную) организацию.
- Современные SMMS, как правило, являются относительно небольшими системами, поэтому линейные размеры магистрали LAN достаточно малы и редко превышают 20–30 метров, а количество станций (узлов) — 10–20.
- В силу ряда причин, в станциях LAN наиболее часто используются восьмиразрядные микропроцессоры и микроконтроллеры семейств x51, i8080/8085, i8088/188 (далее mP). Это объясняется и их доступностью и изученностью и тем, что многие из них de facto стали промышленным стандартом. Для них существует достаточно большой объем верифицированных программ, развитые и хорошо документированные средства программирования и отладки. Их выпускают многие производители, как отечественные, так и зарубежные. Несмотря на значительный возраст, они довольно активно развиваются. Многие из них прошли самые разнообразные исследования, в ходе которых изучалось их поведение в жестких условиях эксплуатации (интенсивных электромагнитных и электростатических полях, при различных излучениях и т. д.). Кроме того, существует психологический фактор профессиональных разработчиков, которые скорее отдадут предпочтение, может, и несовременной, но проверенной и хорошо изученной элементной базе, чем заложат в ответственную разработку новейшую и очень многообещающую элементную базу, которая еще не проверена временем. За примерами далеко ходить не надо. Достаточно посетить сайт Atmel Corp.[2] и посмотреть, сколько уточнений и выявленных в ходе первых лет эксплуатации замечаний опубликовано там на микроконтроллеры AVR, которые при всех их неоспоримых достоинствах, к сожалению, пока еще являются недостаточно верифицированными.
- В качестве станций специализированных LAN SMMS достаточно часто используются мультимикропроцессорные и мультимикроконтроллерные локальные системы. Дело в том, что в некоторых случаях производительности одного mP для решения определенной задачи может не хватить. Можно, конечно, поставить более мощный mP, но это повлечет за собой достаточно большие проблемы: резкое увеличение стоимости, объема «обвязки», усложнение программного обеспечения, сроков разработки и т. п. С другой стороны, даже если производительности mP хватает, иногда, с целью упрощения аппаратной реализации и программного обеспечения, разработчики предпочитают использовать несколько автономных микропроцессоров, каждый из которых решает свою автономную задачу.
- Как правило, в состав современных SMMS включают персональный компьютер PC, на который возлагаются главные функции в системе. Это, конечно же, оправдано. Ведь цены на PC все время уменьшаются, а
объем и возможности периферии, наоборот, растут. Раньше SMMS оснащались собственными узлами связи с периферией, что, конечно же усложняло и оборудование, и программное обеспечение и увеличивало время создания системы. Теперь совсем другое дело! Все необходимое для системы периферийное оборудование можно приобрести в комплекте с PC, причем управление этим оборудованием до предела упрошено! Кажется очевидным, что если уж все периферийное оборудование сосредоточено в одном месте, в PC, то и все управление SMMS также должно быть сосредоточено в PC! Именно так, чаще всего и поступают. Персональный компьютер управляет всей системой, на нем установлена главная программа работы системы, он дирижирует всеми станциями, как оркестром! Он дает команды каждой из станций, что она должна делать. Станции выполняют команды и сообщают об этом PC. Если станция должна в ходе выполнения команды измерить какую либо величину, она посылает в PC и предварительно обработанные результаты измерений (первичная обработка). Получая данные от станций, PC производит их вторичную обработку, накопление, систематизацию, сохранение и визуализацию.
- Очень часто причиной создания SMMS являются жесткие условия эксплуатации в непосредственной близости от объекта управления или измерения, например очень большие электромагнитные поля, в которых PC работать не может. С другой стороны, станция, в силу специфики задачи, должна накапливать большие массивы данных. Это вынуждает разработчиков оснащать некоторые станции очень большими объемами памяти данных, а иногда и организовывать квазидисковые системы. Эти же задачи возникают, если станция должна иметь очень большие библиотеки подпрограмм.
- Достаточно часто станции SMMS располагаются в труднодоступных местах вдали от PC. Поэтому достаточно часто возникает необходимость оснащения станции локальным устройством отображения графической и мнемонической информации о состоянии наиболее важных параметров объекта регулирования. В этих случаях наиболее часто используются промышленные телевизионные индикаторы как наиболее простые и надежные. С другой стороны, это обязывает разработчика организовывать
в отдельных станциях специально организованную память достаточно большого объема, из которой информация постоянно выводится на телевизионный индикатор — видеопамять.
- В заключении приведем достаточно важные требования к современным SMMS, которые разработчикам диктует современная ситуация: предельно низкая стоимость, максимально возможная простота, минимальные сроки разработки, монтажа, модернизации и ремонта.
Перечисленные выше особенности и анализ литературы позволили синтезировать обобщенную (созданную по фрагментам из различных литературных источников) структуру современных SMMS, которая представлена на рис.1.
Проблемы создания
мультимикропроцессорных станций
Рассмотрим организацию станций современных SMMS (см. рис.1). Как уже отмечалось выше, современны е станции SMMS наиболее часто выполняются в виде мультимикропроцессорных локальных систем. Причем количество mP в станциях, как правило, не более двух. Это связано с тем, что организация мультимикропроцессорных систем несколькими mP на одной магистрали значительно увеличивает объем аппаратных затрат (за счет необходимости мониторинга доступа процессоров к магистрали) и усложняет программирование таких систем, называемых сильносвязанными. Обычно используются так называемые слабосвязанные системы, в которых каждый mP имеет свою магистраль со своими локальными ресурсами и работает по своей индивидуальной программе. Связь между магистралями осуществляется через общий глобальный ресурс, в качестве которого могут использоваться: двухпортовые регистры, двухпортовая память или специальные каналы прямого доступа.
Наиболее часто используется связь через двухпортовую память, она
позволяет mP оперативно обмениваться большими массивами данных (в отличие от регистров) и имеет значительно меньшие аппаратные затраты и сложность (в отличие от каналов прямого доступа).
Именно такая двухмагистральная мультимикропроцессорная система станции изображена на рис. 1. Она содержит две магистрали М1 и М2. Наиболее часто для этих целей используется модифицированная магистраль И41 (MULTIBUS-1) [3], из которой исключены все сигналы, связанные с мультипроцессорным арбитражем. На первой магистрали М1 располагается один или несколько микропроцессоров или микроконтроллеров Р1.i (как правило, один mP). Кроме того, на этой же магистрали располагаются аналоговые (MIO) и цифровые (I/O) узлы ввода/вывода, а также может располагаться PROM с библиотеками служебных программ. На второй магистрали М2 располагается второй mP (обычно это достаточно мощный микропроцессор (типа i8088) со своим PROM. Связь между магистралями осуществляется через двухпортовую память GRAM и двухпортовую видеопамять TVRAM.
Аназиз описанной структуры станции позволяет выявить две ее фрагмента, от параметров которых зависит эффективность работы всей структуры.
Во первых, при рассмотрении структуры видно, что mP первой магистрали М1 должен обеспечивать работу с достаточно большим объемом памяти, иными словами, он должен иметь достаточно большое адресное пространство. С другой стороны известно, что практически все восьмиразрядные mP имеют 16-разрядную шину адреса, т. е. объем адресуемой памяти для них соответствует 64К. Из этого следует, что как минимум, процессор первой магистрали должен быть оснащен специальным узлом эффективного доступа к расширенному адресному полю памяти. Такие узлы принято называть диспетчерами памяти (MD).
Во вторых, при связи двух магистралей через двухпортовую память (GRAM и TVRAM) неизбежным становится вопрос об их организации. Ситуация с организацией TVRAM еще более сложная, чем с GRAM, так как на самом деле TVRAM имеет не двухпортовую организацию, а трехпортовую. Третьим источником адресации (доступа) к этой памяти является встроенный генератор телевизионных сигналов, который имеет наиболее высокий приоритет к данным и постоянно осуществляет сканирование данных памяти для вывода их на телевизионный монитор.
Диспетчеры памяти SMMS
Рассмотрим пути реализации диспетчеров памяти MD. К настоящему времени существует достаточно большое количество структур MD [4]. Однако все разнообразие этих структур можно свести к четырем главным структурам, представленным на рис. 2.
Существующие структуры диспетчеров памяти используют «кубовую» или страничную организации памяти. Под термином «куб» понимается объем памяти, эквивалентный полному объему, адресуемому непосредственно микропроцессором. Например, если разрядность шины адреса микропроцессора равна 16 битам, то адресуемый микропроцессором объем памяти равен 64К. Следовательно, один «куб» памяти также равен 64К. Страница — это обычно величина, равная адресуемой микропроцессором памяти, деленной на 2, 4 или 8, т. е. обычно используются страницы с размерами 32К, 16К или 8К.
В основе работы MD лежит принцип выделения различные команды mP для переключения адресов при обращении к ячейке дополнительной памяти. Кубы или ячейки дополнительной памяти обычно называют виртуальной единицей памяти — VMU. Как правило, существующие MD используют логическую или географическую адресацию.
При логической адресации разрядность адресной шины микропроцессора (16 бит) дополняется дополнительными, более старшими линиями адреса, причем временные диаграммы переключения дополнительных разрядов шины адреса соответствуют временным диаграммам переключения основных разрядов шины адреса. Обычно шина адреса дополняется дополнительным старшим байтом, таким образом, получаемая выходная (после MD) разрядность шины адреса составляет 24 бита, а адресуемый объем памяти соответственно может достигать 16М (256 кубов). Дешифраторы адреса при таком способе адресации находятся в каждой VMU.
При географической адресации дешифратор адреса централизован и соединен с каждой VMU индивидуальной линией выборки. Естественно, что при большом количестве VMU, возникают трудности в создании централизованного дешифратора с большим числом выходов и индивидуальных линий выборки. Например, для реализации MD со страничной организацией памяти общим объемом 256К и размером страницы 8К необходим дешифратор с 32 выходами и индивидуальными линиями выборки страницы. По этой причине MD с географической адресацией используются в системах с малым общим объемом RAM, не подлежащим дальнейшему наращиванию (это связано
с переделкой централизованного дешифратора).
Прежде чем приступить непосредственно к рассмотрению структур MD, отметим, что во всех приведенных структурах используются обозначения сигналов в соответствии со стандартом MULTIBUS-I, а в примерах для простоты использованы команды i8080. Использование столь «древнего» микропроцессора обусловлено его широкой известностью. Кроме того, его внешняя структура выводов достаточно близка структуре выводов многих современных микроконтроллеров (например, x51 или AVR).
Напомним основные сигналы стандарта MULTIBUS-I, используемые в рассматриваемых структурах: ADDR — шина адреса; DATA — двунаправленная шина данных; MRDC — линия чтения памяти; MWTC — линия записи памяти; IORC — линия чтения устройств ввода/вывода; IOWC — линия записи устройств ввода/ вывода; INX1 — линия запрета операций с RAM; STSTB — линия признака стековой операции; M1 — линия признака чтения кода команды.
На рис. 2 представлены следующие структуры MD:
a) обобщенная структура MD с логической адресацией и доступом через канал вводавывода;
б) обобщенная структура MD с кубовой логической адресацией и переключением по командам стековых операций;
в) обобщенная структура MD со страничной организацией, логической адресацией и переключением по командам ввода-вывода;
г) обобщенная структура MD с кубовой логической адресацией и переключением адреса по командам косвенной адресации.
Рассмотрим состав и принцип работы каждой из структур, ее достоинства и недостатки.
Структура MD с доступом через канал ввода-вывода (рис 2, а). Дешифратор адреса DC1 ADDR преобразует код адреса ввода-вывода магистрали mP в сигналы управления регистрами старшего RG1, среднего RG2 и младшего RG3 байтов адреса и двунаправленного шинного формирователя данных BD, связывающего шину данных магистрали mP с дополнительной шиной данных. Адрес ячейки VMU устанавливается последовательной записью трех байтов адреса в регистры RG1–RG3 по командам вывода. Доступ к конкретной ячейке VMU осуществляется по команде ввода (вывода) данных [5, 6].
Очевидными недостатками структуры являются последовательное задание адресов,
т. е. большое время доступа к VMU, а также то обстоятельство, что входные и выходные магистрали разделены.
Достоинством структуры является ее простота. Эта структура является наиболее ранней, и в настоящее время используется достаточно редко.
Структура MD с кубовой логической адресацией и переключением по командам стековых операций (рис. 2, б). Дешифратор адреса DC1 предназначен для управления записью старшего дополнительного байта адреса в регистр RG1. Дешифратор команд DC2 предназначен для идентификации признака стековой операции и подключения старшего байта адреса, предварительно записанного в регистр RG1 на время стековой операции. Дешифратор DC3 идентифицирует подключение VMU и блокирует на это время основное RAM по линии магистрали INX1 [7, 8].
Недостатками структуры являются необходимость перед каждым обращением к VMU сохранять текущее значение стека, а после обращения — восстанавливать его, как следствие — большое время доступа.
Структура MD со страничной организацией, логической адресацией и переключением по командам ввода-вывода (рис. 2, в) Особенностью структуры является замена кубов CUBE 1–CUBE N, фигурирующих во всех
предыдущих структурах, на страницы
PAGE 1–PAGE N, причем объем памяти P страницы PAGE связан с объемом памяти C куба CUBE соотношением: C = M х P, где
М — число страниц. Принцип работы структуры заключается в записи командой IOWC адреса страницы в регистр RG1 c определенным адресом ADDR, при этом, выбранная страница памяти накладывается на адресное пространство основного RAM, операции с которым блокируется сигналом INX1.

Недостаткам структуры являются: необходимость перед каждым обращением к VMU вычислять и модифицировать адрес страницы, как следствие — большое время доступа; кроме того, за счет того, что размер страницы меньше размера куба, при равной разрядности шины адреса страничная организация обеспечивает доступ к меньшему объему памяти.
Обобщенная структура MD с кубовой логической адресацией и переключением адреса по командам косвенной адресации (рис 2, г). Структура содержит три дешифратора DC1 адреса, DC2 команды-признака, DC3 используемых кубов, формирователь F и регистр адреса куба обмена RG1. Структура выделяет из общего потока команды косвенной адресации (MOV A, M или MOV M,A) и в фазе выполнения обращения памяти подменяет старший дополнительный байт адреса. Работу структуры поясним с помощью фрагмента программы, приведенного в табл. 1.
Подразумевается, что перед приходом
команды OUT ADDR в аккумулятор занесен байт Z, являющийся в нашем случае и номером (адресом) куба, и байтом, который мы будем записывать в этот куб. В третьем цикле команды OUT ADDR, на шине адреса ADDR установлен адрес регистра RG1, на шине данных DATA — байт Z. По приходу сигнала записи вводавывода IOWC дешифратор DC1 выработает импульс записи, который запишет байт Z в регистр RG1. Дешифратор DC2, стробируемый сигналом выборки команды M1, вырабатывает положительный импульс во время появления на шине DATA одной из команд косвенной адресации MOV A, M или MOV M, A. На временной диаграмме показано состояние внутреннего триггера F1 формирователя F, который при этом устанавливается в «1». Совпадение единичного уровня F1 и нулевого сигнала M1 формирует на выходе формирователя F единичный сигнал F2, который сбрасывается в ноль по приходе следующего единичного импульса линии M1. Единичный импульс F2 на время второго цикла команды MOV M, A (MOV A, M), в течение которого и происходит собственно
запись или чтение, открывает регистр RG1 шину, одновременно дешифратор DC3 блокирует работу RAM нулевого куба. После завершения второго цикла команды выходы регистра RG1 закрываются и программа продолжает выполняться в основном нулевом кубе памяти [9–11].
Проведенные сопоставительные исследования работы описанных структур показали, что самые высокие показатели имеет структура с переключением адресов с помощью команд косвенной адресации (рис. 2, г). Если ее производительность принять за 100 %, то производительность структур a, b и c составляет соответственно 89 %, 57 % и 74 % при чтении байта из VMU и 81 %, 54 % и 73 % при записи байта в VMU.
Пути реализации
двухпортовой памяти
Существует достаточно большое число способов и устройств реализации двухпортовой памяти. Как правило, они основаны на управляемом коммутаторе шин адреса и данных, управление которым осуществляется с помощью аппаратного арбитра, который разрешает обращение пришедшему раньше запросу с одной из магистралей (т. е. открывает коммутатор со стороны этой магистрали) и блокирует обращение со стороны другой магистрали. При этом на блокированной магистрали выставляется флаг занятости, что, естественно, затормаживает работу процессора этой магистрали. В некоторых случаях арбитры выполнялись с приоритетом для одной из магистралей. Однако в более поздних устройствах стали использовать встроенные быстродействующие микроконтроллеры, которые не только выполняли роль арбитров, но и записывали обращение по второй магистрали в промежуточный буфер, данные из которого затем переносились в память (при отсутствии обращения). Такие системы иногда называют памятью с отложенным доступом записи. Эти системы позволяли повысить быстродействие памяти при операциях записи, так как «отложить» операцию чтения без задержки процессора нельзя. В последнее время в особо ответственных системах используются сверхбыстродействующие микросхемы памяти и контроллеров, которые имеют быстродействие на порядок более высокое, чем используемые процессоры. Это позволяет сделать обращение (а точнее, арбитраж) к двухпортовой памяти практически «прозрачным» (незаметным) для микропроцессоров магистралей.
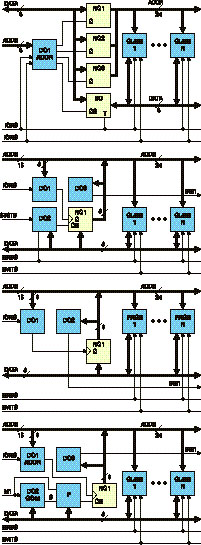
Рис. 2. Структуры MD
Более сложная ситуация возникает при создании двухпортовой видеопамяти. В этом случае в ее составе имеется телевизионный генератор сигналов синхронизации, который все время сканирует память и «замешивает» прочитанные данные в выходной видеосигнал. При этом обращение к такой видеопамяти со стороны магистралей возможно лишь во время кадровых и строчных синхроимпульсов. Для повышения скорости записи в такую память также используется буферизация или другие более сложные приемы.
Проблемы создания
специализированных LAN
Распределенные системы управления существуют уже достаточно давно и на ранних стадиях их развития станции объединялись в специализированные локальные сети. В то время специализированные локальные сети пытались создать по образцу и подобию больших сетей. Каждая из станций, как правило, имела равноправный доступ к магистрали, функции управления и периферия системы были распределены между станциями. Такая организация была оправдана повышенной живучестью таких систем, ведь выход из строя одной из станций не приводил к выходу из строя всей системы, а часть ее функций, например управления, могли взять на себя работающие станции. Недостатками таких систем являлись высокая сложность программного и аппаратного обеспечения как за счет организации равноправного доступа к магистрали, так и за счет оснащения станций периферийным оборудованием с обслуживающей аппаратуры и программным обеспечением.
Кардинально изменилась ситуация лишь в последние несколько лет. С одной стороны, резкое снижение цен на персональные компьютеры сделали их приобретение сопоставимым, а иногда и более дешевым, по сравнению с разработкой специализированной станции, оснащенной периферией. С другой стороны, объем, разнообразие и надежность периферии, да и самих PC намного выросли. Все это предопределило включение PC в большинство современных распределенных систем управления, как впрочем, и в другие системы. Но после включения в состав SMMS персональных компьютеров возникал вопрос: зачем тратить столько времени, создавать сложное программное обеспечение и аппаратуру на создание в каждой станции распределенной системы управления? Как результат — постепенно функции управления сосредоточились у PC. Следующим возник вопрос о необходимости станциям равноправного доступа к магистрали сети. Действительно, если всем управляет PC, то какими сообщениями должны обмениваться между собой станции. Ответ напрашивается сам собой — никакими! Действительно, если PC генерирует станции команду, то она должна либо сообщить ему об исполнении команды, либо передать результаты (данные), полученные в ходе выполнения команды. Таким образом, вырисовывался общий алгоритм работы этих сетей: от PC — команда, от станции — информация. Отсюда и возникло название одного из типов специализированных сетей — командноинформациональные сети [12]. Поскольку эти сети уже были описаны на страницах нашего журнала, более подробно в рамках этой статьи они описываться не будут.
Заключение
Приведенная в статье обобщенная структура распределенных систем управления позволяет создавать небольшие, относительно дешевые, но при этом достаточно мощные и гибкие системы не только промышленного и научного, но и бытового назначения. Основной идеей этой статьи являлось ознакомление читателя с возможностями и проблемами описанной обобщенной структуры и некоторыми путями реализации обозначенных проблем. Хочется надеяться, что полученные читателями знания послужат основой для разработки новых вариантов решения этих проблем и развития распределенных систем управления в целом.
Литература
- Nicolaiciuc O., Gutuleac E., Cheibas V. The main principles of small systems development for manufacturing and research automation // Computer Science Journal of Moldova, 1999, vol. 7, № 2(20), p. 237–246.
- http://www.atmel.com; http://www.atmel.ru.
- ОСТ25 969–83 Система малых электронных вычислительных машин. Интерфейс И41. Технические требования.
- Николайчук О. И. Бежан Л. Ш. Диспетчеризация памяти микропроцессорных систем. // II всесоюз. научн. техн. конф. «Микропроцессорные системы» (Челябинск, 22–24 сентября 1988): тез. докл. — Челябинск.: ЧПИ им. Лен. Комсомола, 1988, — с. 13.
- А. С. 1260955 СССР, МКИ4 G 06 F 9/36 . Устройство для адресации памяти. / А. И. Ляхов, В. Д. Моисеев, В. В. Разумнов,
Э. П. Сенчук, Э.В. Щенов (СССР). —
№ 3884640/24–24; заяв. 15.04.85; опубл. 30.09.86, бюл. № 36. — 4 с.: ил.
- Спарлинг Б. Дж. Периферийная память для микропроцессора Z-80 на динамических ЗУПВ емкостью 64 К // Электроника. 1983, №5, — с. 77.
- А.С.1177820 СССР, МКИ4 G 06 F 13/00 . Устройство для сопряжения процессора с группой блоков памяти / В. В. Снотин.
- Попов С.Н. Спецпроцессор на базе микропроцессора КР580ИК80А в комплексе с мини-ЭВМ. // Микропроцессорные средства и системы. 1986, № 3, — с. 67–69.
- А.С.1160409 СССР, МКИ4 G 06 F 9/36 . Устройство для адресации памяти. / О. И. Николайчук.
- А. С. 1238072 СССР, МКИ4 G 06 F 9/36 . Устройство адресации памяти. / О. И. Николайчук.
- А.С.1414161 СССР, МКИ4 G 06 F 9/36, G 06 F 12/02. Устройства памяти с расширенным адресным пространством./ О. И. Николайчук.
- Николайчук О. Командно-информационные сети — что это такое? // Схемотехника, 2001, № 6, — стр. 26–30; 2001, № 7, — стр. 37–41; http://www.dian.ru/pdf/str26-30.pdf, http://www.dian.ru/pdf/str37-41.pdf; http://www.platan.ru/shem/pdf/str26-30.pdf,
http://www.platan.ru/schem/pdf/str37-41.pdf.
Олег Николайчук
onic@ch.moldpac.md
Ремонт пластика. Ремонт мото пластика. Ремонт пластика скутера. Ремонт пластика.
|


