|
Микросхемы памяти: прошлое, настоящее, будущее
Работа современных электронных устройств зачастую определяется не только параметрами процессора, но и скоростью обмена данными внутри самого устройства. Эта задача во многом решается системой памяти устройства.
Объективно необходимым является соответствие параметров процессора, обрабатывающего данные, и системы памяти, которая по определению обязана их записывать, хранить и предоставлять. Однако здесь существует ряд противоречий.
Во-первых, каждое новое поколение КМОП-структур требует еще более лучшего соотношения скорость/мощность памяти при строгих ограничениях на массогабаритные показатели. Тем не менее некоторые причины, влияющие на временные и энергетические параметры процесса хранения данных и доступа к системе памяти, являются объективно неустранимыми. Например, время задержки в логической КМОП-структуре при коэффициенте разветвления по выходу, равном 4, которое около 10 лет назад составляло 1 нс, сейчас примерно равно
0,1 нс, в то время как время передачи сигнала данных на расстояние 10 см составляет 1 нс.
Во-вторых, использование параллельных структур в процессоре может улучшить его удельные показатели, приходящиеся на чип. Однако межчиповые связи для передачи сигналов не могут быть развиты в той же степени, так как число межчиповых соединений объективно ограничено.
В-третьих, по мере роста плотности размещения элементов памяти требуется больший коэффициент разветвления по выходу, что приводит, по меньшей мере, к логарифмическому росту времени, требуемому для декодирования адреса и соответствующего выбора направления передачи данных.
В итоге, в то время как производительность микропроцессора растет экспоненциально в соответствии с законом Мура, производительность системы памяти не может увеличиваться пропорционально. Качество функционирования системы памяти в большей степени определяется выбором ее иерархии (использование кэш-памяти и т. п.), выбором архитектуры шины передачи данных и характеристиками собственно динамического ОЗУ.
Основными характеристиками ОЗУ, являющегося основным элементом системы памяти, являются [1]:
- информационная емкость, определяемая максимальным объемом хранимой информации в битах или байтах, а также организация памяти (побитно или словами определенного размера);
- быстродействие, характеризуемое временем выборки информации из ЗУ и временем цикла обращения к ЗУ с произвольным доступом или временем поиска и количеством переданной в единицу времени информации в ЗУ (или из ЗУ) с последовательным доступом;
- энергопотребление, определяемое электрической мощностью, потребляемой ЗУ от источников питания в каждом из режимов работы, а также надежность, стоимость, масса, габаритные размеры и пр.
По виду носителя информации ЗУ могут быть ферритовыми, электромагнитными, сегнетоэлектрическими, оптическими, ультразвуковыми, на основе сверхпроводимости и электронными. Среди последних значительное место занимают полупроводниковые ЗУ, выполненные в виде интегральных микросхем [2].
На рис. 1 показана современная классификация микросхем памяти, принятая у нас в стране и за рубежом.
Современные принципы построения систем памяти, в частности динамических ОЗУ, существенно отличаются от своих предшественников. До середины 60-х годов системы памяти ЭВМ строились на запоминающих электронно-лучевых трубках, ферритовых сердечниках и магнитных лентах.
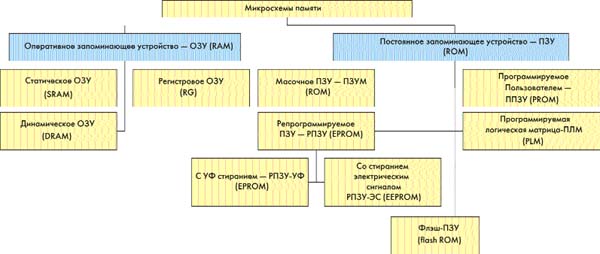
Рис. 1. Современная классификация микросхем памяти
С развитием полупроводниковой технологии устройства, построенные на ее основе, постепенно вытеснили своих предшественников. Сначала стандартным элементом памяти стало шеститранзисторное статическое ОЗУ (SRAM) которое в настоящее время используется в кэш-памяти и в энергонезависимой памяти. Однако настоящий прорыв произошел после изобретения в 1968 г.
однотранзисторного элемента динамической памяти. Идея устройства состояла в объединении конденсатора, заряд которого определял состояние бинарной логики, и МОП-транзистора, позволяющего обратиться к заданному элементу памяти. Несколькими годами позже данное устройство было успешно применено в ОЗУ ЭВМ. Благодаря низкой стоимости на бит и высокой плотности размещения ее элементов, динамические ОЗУ на базе БИС МОП стали доминировать в ОЗУ ЭВМ. Тем не менее существуют объективные ограничения для дальнейшего совершенствования динамических ОЗУ.
Основным ограничением динамического ОЗУ является его производительность, которая включает несколько важнейших аспектов — задержку доступа и длительность цикла доступа к строке и скорость передачи данных при доступе к столбцу. Первые два аспекта относятся исключительно к динамическому ОЗУ, в то время как второй — к интерфейсу устройства памяти и является общим для всех видов полупроводниковой памяти.
Характеристика доступа к строке
В случае организации произвольного доступа к памяти, начиная с доступа к заданной строке, производительность в значительной мере ограничена влиянием RC-задержки при заряде и разряде элемента динамической
памяти и массива в целом. К сожалению, если в элементе статической ОЗУ имеющаяся положительная обратная связь может быть использована для восстановления информации, хранящейся в ячейке памяти, то элемент динамической ОЗУ не обладает возможностью подзаряда конденсатора. Большое значение постоянной времени RC-цепи напрямую
определяется емкостью элемента памяти и сопротивлением ключевого транзистора.
С учетом возможных неточностей при формировании элемента памяти, емкость конденсатора обычно превышает 10–18 для предотвращения потери информации из-за воздействия альфа-частиц космических лучей и радиоактивного фона. Сопротивление же ключевого транзистора не может быть меньше величины, определяемой геометрическими размерами шага его размещения в элементе памяти.
Проблема активного сопротивления усугубляется при перезаписи из-за асимметрии работы ключевого транзистора. Если в качестве такого транзистора используется МОП- прибор с каналом n-типа, процесс перезаписи высокого уровня значительно более длительный. Это следует из того, что транзистор в данном случае выступает в качестве вторичного источника тока при перезаписи. Хотя увеличение напряжения числовой шины или ограничение перепада напряжения в разрядной помогает уменьшить асимметрию, данное явление остается наиболее важным фактором ограничения длительности цикла доступа к динамическому ОЗУ.
Кроме постоянной времени RC-цепи элемента памяти существует аналогичный параметр массива памяти в целом, который определяется иерархией усилителей записи при больших коэффициентах ветвления по выходу, что усугубляет указанную проблему. Хотя данный вопрос не является прерогативой только динамической ОЗУ, здесь он играет существенную роль из-за высокой плотности элементов и динамического характера доступа к ним. На практике удается несколько уменьшить указанный отрицательный эффект, используя двумерный характер связей между элементами памяти и соответствующим образом комбинируя их топологию. С этой точки зрения оптимальным является значение коэффициента ветвления в пределах от 3 до 4, однако жесткие требования к габаритам устройств вызывают необходимость реализации больших значений коэффициента, особенно это касается массивов памяти. Для уменьшения числа элементов решетки, таких как усилители записи числовой шины и усилители считывания, разработчики аппаратуры часто объединяют от 128 до 1024 ключевых транзисторов в каждой числовой шине и от 128 до 256 ячеек в каждой разрядной шине (исключая резервирующие элементы). Для реализации больших значений коэффициента ветвления в современных системах динамических ОЗУ применяют более сложные иерархические структуры, например, разбивают массив памяти на субмассивы.
Кроме того, пиковое значение тока считывания также ограничивает эффективность функционирования памяти. Этот ток появляется при заряде и разряде большой емкости массивной параллельной архитектуры. Быстрая работа с массивом требует больших пиковых значений тока и приводит, таким образом, к большему потреблению энергии, большему перепаду напряжения на сопротивлении и эффекту индуктивности в энергоподводящих цепях.
Характеристика доступа к столбцу
Временной цикл доступа к колонке массива определяется скоростью передачи данных при их фиксировании в считывающих усилителях. Здесь мы имеем дело с мультиплексированием данных (в случае записи) или их демультиплексированием (при считывании) в соответствии с декодированным адресом столбца. Необходимо согласование работы считывающих усилителей и внешних устройств ввода/вывода по скорости. Увеличение числа межчиповых связей приводит к росту стоимости памяти из-за увеличения размеров чипов и размеров корпуса, так как растет число элементов ввода/вывода и штырьков разъема на корпусе. Остается открытой также проблема шумов из-за «дребезга контактов» при увеличении их числа. С другой стороны, увеличение тактовой частоты шины межчипового интерфейса требует адаптации скоммутированных линий к уменьшенным перепадам напряжения. Хотя уменьшение величины перепада напряжения облегчает решение проблемы увеличения энергетического потенциала шины, вызванного увеличением скорости передачи, тем не менее требуемое увеличение скорости передачи в шине все же вызывает постоянную необходимость в совершенствовании источников питания.
Следующим объективным ограничением является проблема обновления памяти, что характерно только для динамических ОЗУ. Утечки заряда в элементе памяти требуют его восстановления через определенные промежутки времени (обычно от 16 до 32 мс). Для ЭВМ данная проблема частично решается использованием магнитных дисков памяти, однако для других приложений систем памяти, например, для энергонезависимой памяти, трудно отказаться от применения постоянного ОЗУ или программируемого ПЗУ с групповым (параллельным) электрическим стиранием (флэш-памяти).
Для эффективного использования преимуществ динамической памяти и нейтрализации ее недостатков разработчиками был предпринят ряд мер. На рис. 2 представлена эволюция архитектуры динамической памяти [3].
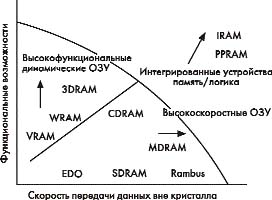
Рис. 2. Эволюция развития архитектуры динамической памяти
В основе совершенствования динамической памяти лежит развитие технологий уплотнения ее элементов, что позволило использовать ее во все более широком спектре практических приложений. Продвижение образцов по оси абсцисс характеризует развитие высокоскоростной динамической памяти за счет увеличения внечиповой скорости передачи данных (уменьшения времени доступа к элементам памяти). Продвижение образцов по оси ординат определяет развитие специализированной или многофункциональной динамической памяти. Здесь основное направление развития заключается в использовании архитектуры построения массива памяти на основе параллельных структур, а именно путем размещения логических элементов перед полностью демультиплексированной шиной данных.
Развитие высокоскоростных устройств динамической памяти началось в конце 1980-х годов. Лучшие образцы демонстрировали время произвольного доступа к памяти менее 20 нс и время доступа к колонке менее 10 нс, что на 2–3 порядка превосходило параметры применявшихся в то время систем оперативной памяти объемом
1 Мбит. Используя КМОП технологию, специалисты IBM улучшили адресные ключевые и декодирующие схемы, архитектуру массива памяти и цепи передачи данных.
В частности, постоянная времени RС-цепи в массиве была уменьшена путем применения двухуровневых металлических перемычек для числовой шины. Была также усовершенствована система перезаписи.
Разработчики из Hitachi обеспечили повышение скорости доступа к динамической памяти, комбинируя биполярный транзистор
с большим коэффициентом усиления и КМОП-структуры, то есть создав Би-КМОП технологию.
В те времена скорость обработки данных в микропроцессорах не слишком превосходила скорость доступа к динамической памяти — достаточно было сравнительно небольшой кэш-памяти для широкого применения динамической памяти в приложениях. Однако первое поколение высокоскоростной динамической памяти явилось скорее вехой в научных разработках, чем революцией в коммерческом внедрении предложенных технологий.
Ускоренная передача данных
В поколении 4 Мбит EDO (Extented Data Out) увеличение скорости передачи данных при доступе к колонке обеспечивалось добавлением дополнительной конвейерной обработки в выходном буфере при сохранении общепринятого асинхронного интерфейса. Отличие заключалось в том, что данные сохранялись в конце действующего сигнала строба доступа к колонке вплоть до начала следующего цикла доступа к колонке. Такая организация доступа позволяет улучшать характеристики памяти с минимальными изменениями в микропроцессорной сборке контроллера памяти. Типичная EDO 4 Мбит с х8 I/O, работающая с тактовой скоростью цикла доступа к колонке
33 МГц, может обеспечить пиковую скорость передачи данных 266 Мбайт/с на чип.
В поколении 16 Мбит синхронная динамическая оперативная память (SDRAM) использует уже высокоскоростной синхронный интерфейс. Используя конвейерную обработку данных или предварительную выборку нескольких бит за время, превышающее задержку шины передачи данных, разработчики увеличили скорость передачи данных при доступе к столбцу. Были также улучшены показатели произвольного доступа путем перемежения мультиплексируемых фрагментов массивов памяти (обычно двух) в одном чипе. Пиковая скорость передачи данных в SDRAM 16 Мбит с х16 I/O и тактовой частотой 66 МГц составила 1,1 Гбит/с (133 Мбайт/с) на чип. Пакетный режим работы также устраняет необходимость адресования столбца при каждой передаче данных даже в случае изменения длины пакета в сверхцикле.
Ускорение доступа к памяти
Несколько усовершенствований было направлено на приближение показателей доступа к строке в DRAM к уровню показателей, характерных для SRAM. Это было
достигнуто интегрированием небольшого количества SRAM или делением DRAM
на несколько независимых фрагментов. EDRAM (Enhanced DRAM) имеет распределенный кэш, в то время как кэш CDRAM (Сached DRAM) локализован. Хотя обычная DRAM может использовать усилители считывания как распределенный кэш, внешние буферы в EDRAM и CDRAM могут увеличить коэффициент попадания. В MDRAM (Multibank DRAM) для графических приложений и кэш-памяти доступ к строкам улучшен путем объединения на общем чипе многих независимых 256-килобитных сегментов (банков) DRAM. Чип обеспечивает среднее время доступа, которое превосходит время доступа к колонке вследствие независимости обработки отдельных сегментов и, таким образом, улучшает доступ к строке и восстановление памяти.
Революция в интерфейсе
систем памяти
Rambus DRAM использует интерфейс памяти пакетного типа. Исходная версия реализует пиковую скорость переноса данных 500 Мбит/с на штырь электрического соединителя (и 4 Гбит/с или 500 Мбайт/с на чип)
с генератором тактовых импульсов на
250 МГц. Высокая скорость передачи данных на чип необходима в таких приложениях, как игровые машины и видеокарты, где требования к уровню гранулярности системы памяти невелики, а требования к скорости передачи данных большие. В режиме ожидания массив DRAM активен (данные сохраняются в усилителях считывания), и его регенерация происходит только после поступления нового адреса строки, отличающегося от предыдущего, что происходит при окончании страницы памяти.
Улучшенная версия данного устройства, называемая Concurrent Rambus, реализует пиковую скорость переноса данных 600 Мбит/с на штырь электрического соединителя с более эффективным протоколом для обеспечения большей скорости передачи. Мультиплексирование адресов и данных уменьшает число вводов-выводов, хотя максимально достижимая скорость передачи при этом несколько уменьшается, особенно для распределенного доступа.
Высокофункциональные DRAM
Наряду с развитием технологии высокоскоростных DRAM возрастает необходимость создания узкоспециализированной динамической памяти. Особенно показательным является создание чипов памяти для приложений машинной графики. Первым коммерчески успешным проектом специализированной DRAM явилась VRAM (Video RAM). Внедренная в середине 80-х годов, она реализовала идущий параллельно двухпортовый доступ путем мультиплексирования параллельных данных в массиве DRAM, после этого данные демультиплексируются при их распределении по колонкам. Обновляемые данные видеокартинки, накопленные в усилителях считывания, сначала передаются в последовательные регистры, расположенные около усилителей считывания, а затем передаются на экран через отдельный порт последовательного доступа. Таким образом, разница между произвольным и последовательным доступом оказывается небольшой. В итоге при передаче данных блоками по 4096 бит между усилителями считывания и последовательными регистрами, работающими с тактовой частотой
10 МГц, внутренняя скорость передачи данных составила 41 Гбит/с (5,1 Гбайт/с) —
уровень, недостижимый в других образцах высокоскоростной DRAM. Однако VRAM довольно дорога, так как размещение последовательных регистров около считывающих усилителей усложняет конструкцию и занимает большую площадь кристалла.
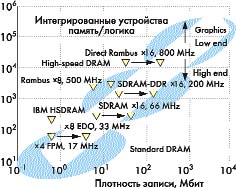
Рис. 3. Диаграмма развития динамической памяти в координатах «скорость передачи данных —
плотность записи»
WRAM (Window RAM) улучшила работу графики в графической среде пользователя. Вместо размещения регистров около считывающих усилителей разработчики поместили их вне массива DRAM. Данные для обновления картинки переносятся со скоростью около 2,1 Гбайт/с по внешней шине. Таким образом, конструкция стала проще и дешевле.
3DRAM была разработана специально для ускорения работы с трехмерной графикой. Последовательные регистры здесь также размещаются вне матрицы памяти.
Интегрированная технология
«память/логика»
С точки зрения архитектуры компьютеров интеграция памяти и логики берет свое начало в разработках с 1970 г. Однако исследования в области интеграции DRAM и проблемно-ориентированной (специализированной) интегральной микросхемы (Application-Specific Integrated Circuit или ASIC) были осуществлены относительно недавно. Тем не менее, технология «память/логика» уже внедрена в ряде разработок, таких как чип типа «интегрированный графический контроллер плюс фрейм-буфер» во многих ноутбуках, а также интегрированный чип типа «центральный процессор плюс динамическая память», предназначенный для вложенных приложений. Можно сказать, что данная интеграция широко внедрена в производстве систем памяти, так как чипы памяти обычно имеют в своем составе логические элементы (декодеры адреса и ключевые схемы). Тем не менее данному технологическому направлению еще предстоит длительное развитие.
Современная методология
разработки динамических ОЗУ
Целью разработчиков было создание динамической памяти большой величины («макро»), оптимальную по показателю плотность/универсальность, а также динамического ОЗУ большой величины, пригодного для применения в устройствах, разработанных на основе стандартных принципов ASIC. Динамическое ОЗУ «макро» представляет собой комбинацию массива динамического ОЗУ и дополнительных устройств, что позволяет создать функциональную память с минимальной степенью ее детализации для интеграции с другими логическими устройствами. Интерфейс и число входов/выходов устройства данного типа могут значительно отличаться от аналогичных параметров автономной схемы динамического ОЗУ, так как «макро» не требует дополнительных устройств для взаимодействия с другими элементами конкретного электронного устройства. Основной проблемой для разработчиков явилось обеспечение требуемой гибкости в конфигурации, например, в числе строк и столбцов и числе входов-выходов с одной стороны, а также плотности элементов памяти, достижимых в автономных БИС динамической ОЗУ, с другой стороны.
Ключевое направление исследований в архитектуре и дизайне сверхвысокой степени интеграции в данной области — создание архитектуры чипов, использующей свойство широкодиапазонности, характерной для параллельной архитектуры данных в массиве. Даже когда диапазон возможного числа строк в массиве громаден, для повышения гибкости связи массива динамического ОЗУ и логических устройств может быть эффективно применена архитектура типа однокристальной шины данных.
Смешанная технология «память/логика» явилась основой развития архитектуры продвинутых компьютерных систем со сверхплотными динамическими ОЗУ вплоть до поколений ОЗУ со скоростями передачи данных 256 Мбит и 1 Гбит. Возможность применения такой архитектуры рассматривают исследования в области IRAM (интеллектуальной ОЗУ) и PPRAM (ОЗУ с параллельной обработкой). IRAM объединяет технологии процессоров и динамического ОЗУ для обеспечения широкого диапазона в случае предсказуемого доступа, такого как перемножение матриц, и малого времени ожидания для непредсказуемого доступа, такого как доступ к базе данных. Это предполагает использование технологии «память/логика» уровня
1 Гбит. PPRAM интегрирует четыре элементарных процессора, каждый из которых состоит из четырех 32-битных RISK-процессоров, 8-мегабайтного динамического ОЗУ и 24-килобайтного кэшированного статического ОЗУ, использующего технологию «память/логика» уровня 256 Мбит.
Рисунок 3 показывает пиковые значения скорости передачи и плотности записи существующих динамических ОЗУ в областях существующих практических приложений.
Из рис. 3 следует, что основной причиной развития технологии динамических ОЗУ явилась потребность в графических приложениях и аппаратных средствах, предоставляющих не все возможности, доступные в более дорогих моделях, либо из-за того, что применяемая в них технология устарела или близка к устареванию, либо из-за того, что они предназначены для начинающих (так называемый low end сегмент рынка). Высокоскоростное динамическое ОЗУ обеспечит меньшую гранулярность системы памяти при заданных требованиях к пропускной способности.
Если экстраполировать тенденцию, то видно, что рост требований к скорости и плотности записи динамического ОЗУ вызывает необходимость создания нового поколения высокоскоростной динамической памяти. Во многих приложениях это будут интегрированные чипы «память/логика».
Существует три основных кандидата в следующее поколение динамических ОЗУ. Первой в ближайшей перспективе, вероятно, будет SDRAM-DDR (SDRAM с удвоенной скоростью передачи данных), которая в отличие от существующей SDRAM использует синхронные стробы адресов строки и столбца (RAS и CAS). Скорость переноса данных может быть увеличена путем их передачи с обоих концов генератора тактовых импульсов. Таким образом, 16-мегабитовая SDRAM-DDR с х16 I/O, работающая с генератором на 100 МГц, может обеспечить
3,2 Гбит/с.
Второй кандидат, Direct Rambus DRAM, является улучшенной версией линии Rambus DRAM и, как ожидается, обеспечит пиковую скорость передачи данных 13 Гбит/с на чип. Такая скорость будет обеспечена за счет использования генератора тактовых импульсов на 400 МГц и шины на 16 бит.
Третий кандидат, SLDRAM, была усовершенствована путем применения SCI (Scalable Coherent Interface — масштабируемый когерентный интерфейс).
За высокоскоростными динамическими ОЗУ лежит область интегрированной технологии «память/логика». Это объясняется усложнением вопросов энергопитания устройств и необходимостью размещения электронных компонентов на малой площади, что особенно характерно для мобильных приложений. Причем вопросы энергопотребления обостряются как для внутричиповой передачи данных, так и для межчиповой, при условии сохранения полосы пропускания памяти между микропроцессором и динамическим ОЗУ. Движение в сторону интегрированных технологий ускоряется также развитием устройств с малой памятью для рынка «низкого уровня».
Данная ситуация имеет более общий характер, так как пропускная способность системы памяти растет медленнее, чем плотность записи динамического ОЗУ, стоимость устройств такого типа не меняется, а стоимость на бит не уменьшается так быстро, как растет плотность записи динамического ОЗУ. Другими словами, стоимость чипов новых поколений непрерывно растет и без уменьшения общего числа чипов в системе памяти, сохранить постоянной ее стоимость невозможно. Изменения же цен на кремний носят долговременный характер.
Тем не менее смещение в сторону интегрированных технологий может оказаться достаточно медленным. С технической точки зрения достаточно сложна интеграция элементов памяти и логики в одном чипе. С коммерческой точки зрения пользователи элементной базы стремятся применять проверенные технические решения, соответствующие определенным стандартам. Необходимо существенное превосходство новых технологий перед уже существующими, чтобы преодолеть стереотип мышления конструкторов электронных систем.
Возрастающий уровень интеграции инициирует смещение из области специализированных чипов в область интегральных технологий «память/логика». Учитывая то, что данная интеграция может затянуться, хорошей временной альтернативой может явиться размещенный в динамическом ОЗУ сопроцессор, что обеспечит лучшее сочетание архитектуры и технологии.
В настоящее время уже появились эффективные устройства, сочетающие в себе функции логики и памяти. Одним из примеров таких устройств является EasyFLASH — конфигурируемая система памяти на кристалле для 8- или 16-битных процессоров. Данное устройство существенно упрощает процесс увеличения флэш-памяти в устройствах, основанных на применении микропроцессоров.
Литература
- Лебедев О. Н. Применение микросхем памяти в электронных устройствах. Справочное пособие. — М.: Радио и связь, 1994. — с. 210.
- Дерюгин А. А., Цыркин В. В., Красовский
- Е. и др. Применение интегральных микросхем памяти. Справочник. — М.: Радио и Связь. 1994. — с. 232.
- Yasunao Katayama. Trends in Semiconductor Memories. — IEEE Micro, 1997, Nov/Dec.
P. 10–17.
Владимир Дмитриев
semiconduct@pit.spb.ru
|


